
Record linkage: master data strategy

Introduction
Record linkage or Fuzzy matching is the task of matching records from different data sources that do not have common identifier, often called Primary Key in database world like Social Security Number (SSN). Why do we want to do it? One reason is we want to enrich one of the datasets with information from another.
For example we can link records of hospital treatment records and police data to understand severity of certain road accidents. Hospital will have severity of injury, extent of treatment, number of days patient in hospital while police will have crash details like road condition, location of crash, time of the day etc. One may be interested in understanding how these aspects are related. We can match the databases on patient name and details.
What causes the mismatch
When data is recorded in different databases or ERPs there is a chance of fields to diverge for same record, also called entity. For example you maybe using seperate services of a say a telecom company or say a bank and there may be some differences in your detail between the two accounts. This may be the reason when you call customer support you may have to give all your details again if they transfer you to new department as their customer database may be different. This can happen because some attributes of same entity which is you the customer are different in database either because
- fields recorded incorrectly - like spelling error in name or lack of standardization First Name, Second Name order etc
- fields changed - like changes in address or phone numbers
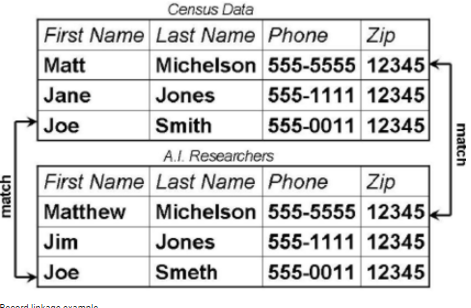
When the dataset is small humans do a very good job in matching record but this can be tricky challenge when datasets are large and simple excel vlookup fail as there may be no exact match.
Why do business care
Business wants to have a Single View of Customer or Entity, also called Mastered Data. This makes decision making easier and business processes smoother. What needs to be done is connect the data silos.
For example in business context matching records of telecomunication constumers on their address to understand how many services or products a household is consuming e.g. mobile service, internet and streaming so the companies can offer a cumulative package to customers based on their household usage. It is possible customer records of different services are stored in seperated databases and record linkage maybe needed. Why this can be useful - it is generally given that consumers with multiple services tailored for them tend not to jump to different service provider.
In my case the requirement was consolidating Technical Equipment records in different ERP and legacy application databases which are used by different departments - Maintenance, Finance and Manufacturing. These different databases do not have a common unique identifier and data quality issues mean there is error in how same records are stored. In absence of robust record linkage a manual matching and validation is required - this requires lot of human intervention and bandwidth.
The record linkage tool and approach with ability to scale and automate matches is key here.
Here in this post I give an overview of 3 stages record linkage journey. Often one starts this journey and can stop at stage 1 or 2 based on their use case.

1 Rule Based Match
In Rule based match you build some rules from subject matter experts like match SSN and if SSN not present then match names and DOB, location.
In SQL it will look like Matches from Rule1
SELECT * FROM DATASET1 DB1
INNER JOIN DATASET2 DB2
ON DB1.SSN=DB2.SSN
Matches from Rule2
SELECT * FROM DATASET1 DB1
INNER JOIN DATASET2 DB2
ON DB1.SSN != DB2.SSN
And DB1.NAME=DB1.NAME AND DB1.ADDRESS=DB1.ADDRESS
To do this one must have domain knowledge and understanding of dataset. Requires preprocessing as like standardizing the upper or lower care, parsing and splitting string, standardizing the strings to have special character or not like zip code with hyphen or not.
2 Probablistic Match
Probabilistic Match approach came about in 1960s to match census data. This matching is based on the fact that each record has multiple attributes and in ideal world all attributes match for same record in two databases. But as we know in real world matching records will have some attributes different.
This method uses the fact some fields will match purely by chance for non-matching records like Date of Birth and while there is a chance that some fields can mismatch for same entity, for example my name is often misspelled as Ajay.
Weights are assigned to each attributes to correctly estimate match and non-match, these weights then used to calculate probability that the records from different dataset are same or not. Below are steps to gets probabilistic match
- Assign match and non match probabilities: Lets say one of the attributes for a match is Date of Birth (DOB) of a person exisiting in two different datasets. Then DOB of matching purely by chance for different people (non-matches) is 1/365 or 0.27% called µ and it can be estimated that for same person (matching record) the probability of DOB matching is 95% (DOBs can be blank or have errors in datasets hence not 100%) called m
- Run comparison of the attribute DOB in this case for each record from dataset1 and dataset2. If attributes match then a Match weight is assigned which is m/u and if attributes don’t match then it is (1-m)/(1-u). In short if there is match the weigt will be high and if attributes don’t match then weight is low.
- Do this for each attribute then add up the weights. If the total is above a threshold then the records are a match and if total low then it is a non-match. For weigths total in middle then a human review will be required.
- Threshold setting is balancing act of acceptable recall and precision a. Recall – Proportion of true matches that are linked by algorithm. I think of this as ability of algo to identify a match b. Precision – Proportion of algo matches that are true matches. I think of it as estimator of correctness.
- Tune the probabilities based on the results and understanding on the datasets
Advantage of this approach is the weights can be trained to get away from building complex rules and requires less human intervention.
Disadvantage is it is computational heavy as all record pairs have to compared and scored. If the size of datasets are N and M rows respectively then order of matches when need analyzing will be in order of M x N. One way to get around this is called ‘Blocking’, which only compare records where one of the attributes is same for e.g. compare people whose City of Birth is same. This is significantly reduce the comparison.
3 Machine Learning
ML classification algorthms are used to divide records pairs into matches and non-matches. These algos fall into
- Supervised – The use training data to learn classification for e.g. logistic regression
- Unsupervised – These algorithms do not need training data e.g. K-means clustering
I found Python Record Linkage Toolkit has capabilities like:
- Ability to define the types of matches for each column based on the column data types
- Use “blocks” to limit the pool of potential matches
- Provides ranking of the matches using a scoring algorithm
- Multiple algorithms for measuring string similarity
- Supervised and unsupervised learning approaches are available
The problem I faced was it is a little complicated to wrangle the results in order to do further validation. However, the steps are relatively standard pandas commands so do not let that intimidate you.
credits: Title image - [El cajista]